2.3. Количественная оценка поглощений поездок
Классификационный анализ. Используемая в настоящее время в транспортном моделировании модель классификационного анализа применяется здесь с учетом последних модификаций и опыта использования раннего варианта модели, предложенного П. Гудменом [26]. Значительная часть излагаемого здесь материала посвящена сбору по возможности точной и полной информации, используемой как на входе модели генерации поглощений, так и для получения натурных данных для последующего сравнения с модельными результатами. Использовавшийся вид модели поглощений представляет собой незначительно модифицированный вариант метода, применявшегося в работе Selnec [46]. Основные различия сводятся к тому, что в нашей модели генерации поглощений учитывается только связь между количеством автомобилей, находящихся в личном пользовании, и размерами дохода, а также меньше групп, выделяемых по признаку расселения жителей. В частности, поскольку в моделях распределения пассажиропотоков по маршрутам и видам транспорта используется дезагрегированное описание типов пассажиров, мы придерживаемся процедуры генерирования поглощений, принятой в работе [46], с разбивкой пассажиров скорее по их типам, чем по видам транспорта, т.е. так, как это первоначально предлагалось в работах [24, 67]. В отдельных случаях в качестве базового года взят 1966 г.
Входные данные. Генерирование поездок и пунктов их назначения зависят от региональных характеристик района исследований и социально-экономических признаков каждой зоны. Соответствующие данные принадлежат к числу важнейших входных элементов модели. Большую часть этой информации нетрудно получить, обратившись к данным переписей по административным районам. Чаще всего границы выделяемых нами зон совпадают с границами административных районов, кроме разделенного на четыре района г. Бредфорда, а также района г. Лидса (28 зон). Для последних надежным источником информации является библиотека Уорда (Ward Library), но для получения более подробных сведений о занятости с разбивкой по сравнительно небольшим зонам пришлось обратиться в Бюро переписи и обследования населения, где и были подготовлены специальные данные о поездках на работу [14].
В моделях используются следующие входные данные. Для генерирования поездок: численность населения, количество отдельных семей, численность населения, проживающего в отдельных домах, число работающих жителей, число семей с разбивкой по количеству принадлежащих им легковых автомобилей (0,1 или 2 и более автомобилей).
Для генерирования поглощений используются данные о числе занятых в различных отраслях производства, числе учащихся, числе занятых в сфере коммунального хозяйства, в сфере услуг, на транспорте, в связи, в розничной торговле, в сфере распределения, в государственном аппарате и о числе лиц свободных профессий.
Отсутствие данных о подвижности отдельных групп семей по графству Западный Йоркшир вынудило пользоваться коэффициентами подвижности и параметрами распределения, полученными для других районов Англии. Сведения о мобильности населения в требуемом виде имеются для конурбации на Севере Англии [46].
При этом, однако, пришлось вносить поправки в коэффициенты поглощения поездок, которые дезарегировались по пяти группам плотности рабочих мест. Параметры распределения, использованные при определении группировки семей, взяты из [24] и [67]. Естественно, в идеальных условиях такие распределения калибруются по данным семейной статистики.
Классификация семей. Основная часть работы, выполнявшаяся в ходе классификации населения, сводилась к обобщению сведений по 108 группам семей на базе предположения о том, что принятые для этих групп коэффициенты генерирования поездок не изменяются затем во времени и пространстве. Эти группы описываются в многомерной классификации по признакам размера дохода семьи, числу принадлежащих семье легковых автомобилей, а также по структурным признакам семей, перечисленным ниже.
Группировка жителей по размерам семейного дохода (по данным о годовых доходах семей в 1966 г.)

Группировка семей по числу автомобилей во владении

В случае когда гамма-распределение сводится к экспоненциальному с отрицательным показателем, коэффициенты берутся в следующих значениях: a1 = 1,15; b1 = 0; c1 = 0,8.
Для семей, владеющих одним автомобилем: а2 = 1,64; b2 = 2,24; с2 = 1,31.
Вероятности для группы семей, владеющих двумя и более автомобилями (N=3), определяются равенством
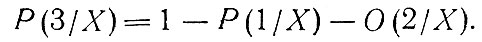
Значения этих вероятностей независимы от местоположения зон и приведены в табл. 2.1. Для всего рассматриваемого района используется один закон распределения. Авторы не исследовали возможности использования семейства кривых, отражающих изменения в соотношениях размеров владения автомобилями и дохода семьи в разных условиях плотности населения [36].
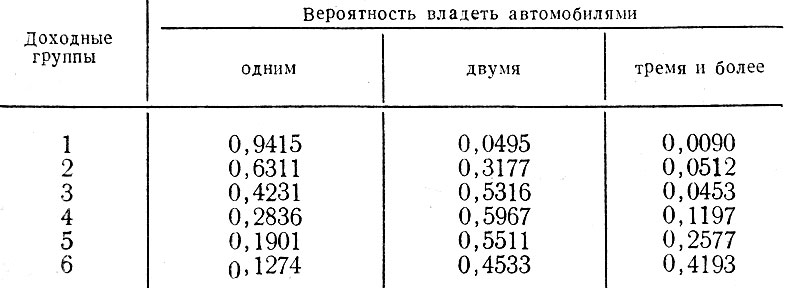
Таблица 2.1. Вероятности владения легковыми автомобилями при заданных размерах дохода
Процедура вычисления вероятностей получения разных доходов. Для получения значений вероятностей тех или иных размеров дохода для проживающих в каждой зоне семей, относимых к шести доходным группам, необходимы данные о средних размерах доходов по каждой зоне. Когда таких данных нет в первичной форме, их можно вычислить, пользуясь ранее составленной зависимостью числа автомобилей, принадлежащих семье от размеров дохода и на основании известной из переписи информации о наличии автомобилей у населения. В работе [46], где данные о размерах дохода и о владении легковыми автомобилями были известны из статистики, размеры годового дохода за базовый год с разбивкой по зонам были вычислены с использованием модели, базирующейся на инвертированной зависимости между числом автомобилей, принадлежащих семье, и размером ее дохода.
Оказалось возможным при прогнозировании "ослабить последствия неточности модели определения количества легковых автомобилей в личном пользовании, введя понятие псевдосреднего дохода, согласующегося с размерами владения автомобилями в данной зоне".
Необходима какая-то итеративная процедура поиска, при которой зоны рассматриваются поочередно со случайно выбранным начальным значением среднего дохода семьи X, которое постепенно уточняется. Это выбранное значение предполагается гамма-распределенным в каждой зоне [67]. Вероятность I(Х) принадлежности семьи к одной из шести доходных групп вычисляется интегрированием [1]:
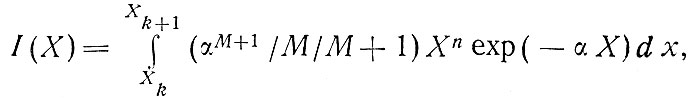
где
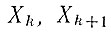
- граничные доходы каждой из шести групп. В случае группы высшего Дохода верхний предел принимается равным 15 тыс. ф. ст.
Параметры распределения, а также m являются функциями среднего дохода
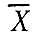
и стандартного отклонения δ2:
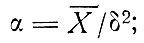
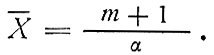
Параметр α определяет распределение доходов относительно среднего значения и вычисляется по (2.8) при m = 1,636, как предложено в [67]. Эта процедура отличается от той, которая использовалась в работе [46], где а определяли из уравнения (2.8), зная среднее значение и дисперсию. В работе [46] для всего рассматриваемого района принята постоянная величина α = 1,56 и различный для разных зон параметр т, тогда как в данном исследовании приняты зависящий от местоположения зоны параметр а и неизменный параметр m. Методом, принятым в [46], подразумевается, что с увеличением размеров среднего дохода в зоне дисперсия соответствующего распределения значений дохода изменяется сходным образом (см. табл. 2.1). В то же время, нашим методом подразумевается, что дисперсия увеличивается быстрее, чем среднее значение дохода (табл. 2.2).
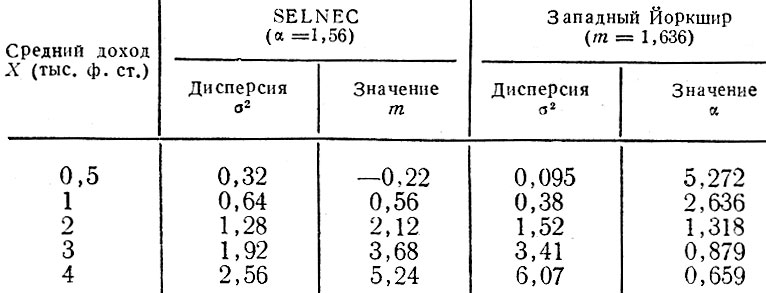
Таблица 2.2. Зависимость между средним доходом и дисперсией размеров дохода, полученная в работе (46) и в работе для графства Западный Йоркшир
Она увеличивается в 4 раза с удвоением среднего размера дохода.
После определения I(Х) полученную зависимость можно использовать в сочетании с вероятностной зависимостью размеров владения некоторым количеством автомобилей от размера дохода для прогнозирования вероятности принадлежности жителей каждой зоны к одной из трех групп, выделенных в зависимости от числа принадлежащих семье легковых автомобилей:
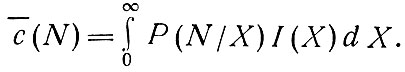
Фактически это уравнение использовалось в виде, учитывающем дискретное распределение по размерам дохода:
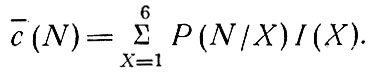
Здесь точность первоначально заданных значений X проверяется вычислением частот распределения, реально наблюдаемых для рассматриваемой зоны:
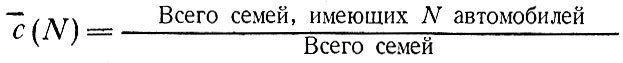
и их сравнением с
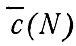
Вычисляется взвешенная сумма S квадратов разности между прогнозируемыми и наблюдаемыми значениями частот:
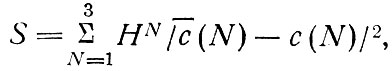
где HN - данные наблюдений о числе семей, принадлежащих к каждой из трех групп, выделенных по признаку принадлежности семье того или иного числа легковых автомобилей.
Процедура вычисления значений по формуле (2.6) повторяется вплоть до нахождения значения X, минимизирующего S. Данный процесс автоматизирован с помощью метода Пауэла [2] и занимает приблизительно 80% времени вычислений всех групповых характеристик.
Определение характеристик семейной структуры. Значения соответствующих вероятностей получаются из сочетания пуассоновского распределения размеров семей и биномиального распределения работающих жителей [36]. Предполагается, что вероятность того, что f членов семьи, состоящей из z членов, работает, описывается биномиальным распределением
где G(z) - вероятность того, что какой-то член семьи, состоящей из z членов, работает.
В типичном случае значение G(z) полагается постоянным и независимым от z [36] и приравнивается к частному от деления числа работающих на общее число семей.
Вероятность того, что семья состоит из z членов, определяется формулой:
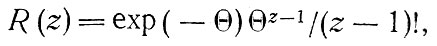
где z - средний размер семьи.
Совместная вероятность того, что в семье, состоящей из z членов, работает f членов, равняется произведению вышеприведенных вероятностей:
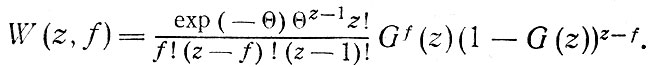
В работе [36] приведены соответствующие виды этого распределения, необходимые для оценки вероятности принадлежности семьи к одной из шести структурных групп.
Условные вероятности. После получения распределения вероятностей для трех выделенных признаков семей остается объединить их таким образом, чтобы получить вероятностные характеристики событий N, X, z, f для всех 108 групп семей.
1. Наихудшим из возможных сочетаний будет такое, при котором предполагается независимость отдельных распределений:
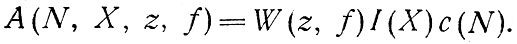
Очевидно, не имеет смысла пользоваться этой формулой, когда имеются значения условных вероятностей владения автомобилями в зависимости от размеров дохода, которые использовались при оценке средних размеров дохода по зонам и при определении c(N).
2. Лучшее, что можно сделать в существующих условиях, это объединить распределения следующим образом:
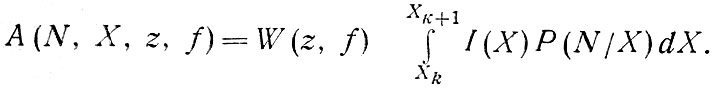
3. В идеальном случае можно получить информацию об условных вероятностях относительно структуры семьи, размеров дохода и количества автомобилей, находящихся в личном пользовании. В [46] отмечается: "Очевидно, эти распределения не являются независимыми в том смысле, что различные составы семей будут характеризоваться неодинаковыми признаками размера доходов и, следовательно, различными вероятностями владения тем или иным количеством легковых автомобилей. Так, если в группе семей много одиноких пенсионеров, то, очевидно, характеризующие их признаки размеров дохода и владения автомобилями будут отличаться от признаков других групп". Еще одну иллюстрацию этой условной зависимости можно видеть в данных переписи по конурбации графства Западный Йоркшир. Табл. 2.3 показывает, что число работающих в расчете на семью больше в семьях, владеющих легковыми автомобилями, чем в семьях, не имеющих своих автомобилей.
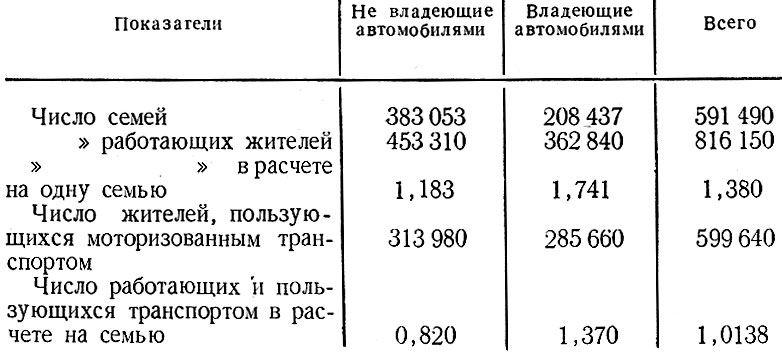
Таблица 2.3. Сведения о жителях Западного Йоркшира
Генерация поездок и их поглощение. Число поездок из зоны i определяется как произведение коэффициентов подвижности на число семей в каждой из 108 групп населения в данной зоне:
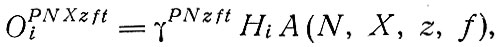
где Р - цель поездки; t - время суток (обычно часы пик).
При генерации подробно классифицированных поездок требуется агрегирование результатов до уровня, удовлетворяющего входным требованиям модели распределения поездок.
В нашем случае необходимо сохранить условные обозначения поездок и частично дезагрегированные данные о владении автомобилями:
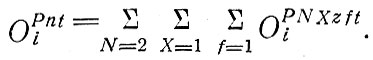
В настоящей работе t относится к периоду, равному суткам. Индекс n указывает, генерируется поездка для семьи, владеющей автомобилем (n=1), или нет (n=2).
Модель поглощения поездок непосредственно использует входные данные, относящиеся к характеристике зоны, а также коэффициенты поглощения поездок за сутки
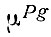
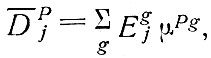
где Egj - число, соответствующее мере привлекательности зоны j по виду деятельности (назначению поездок) g.
Значения
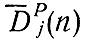
представляют собой первые (немасштабированные) оценки числа поездок с определенным целевым назначением, совершаемых в каждую зону. Можно высказать дополнительное соображение, важное для этапа распределения поездок при использовании модели с двумя ограничениями, а именно, напомнить об условии
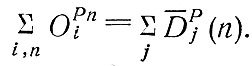
Маловероятно, что это условие будет выполнено без "подгонки" какой-либо части уравнения, а поскольку обычно считается, что модели генерации поездок (выездов) более адекватны действительности, то размеры поглощения корректируются следующим образом:
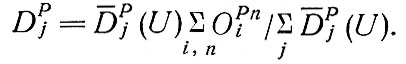
|
ПОИСК:
|
При использовании материалов сайта активная ссылка обязательна:
http://motorzlib.ru/ 'Автомобилестроение, наземный транспорт и организация движения'